Module 4 of the Agentic AI Mastery Course by Dr. Ananjan Maiti
From Prototype to Production: The Deployment Challenge
Building an AI agent that works in a controlled development environment is fundamentally different from deploying one that operates reliably in production. Development agents can tolerate occasional failures, hallucinations, and inconsistent behavior. Production agents cannot. The gap between a working prototype and a production-ready system is where most agentic AI projects fail — not because the core technology is inadequate, but because the engineering practices around safety, evaluation, monitoring, and integration are insufficient.
This module addresses the critical practices and technologies required to bridge that gap: the Model Context Protocol for standardized tool integration, guardrails for safety and compliance, evaluation frameworks for measuring agent performance, and enterprise architectural patterns for scalable, maintainable agent deployments.
Model Context Protocol: Standardizing Agent Tool Integration
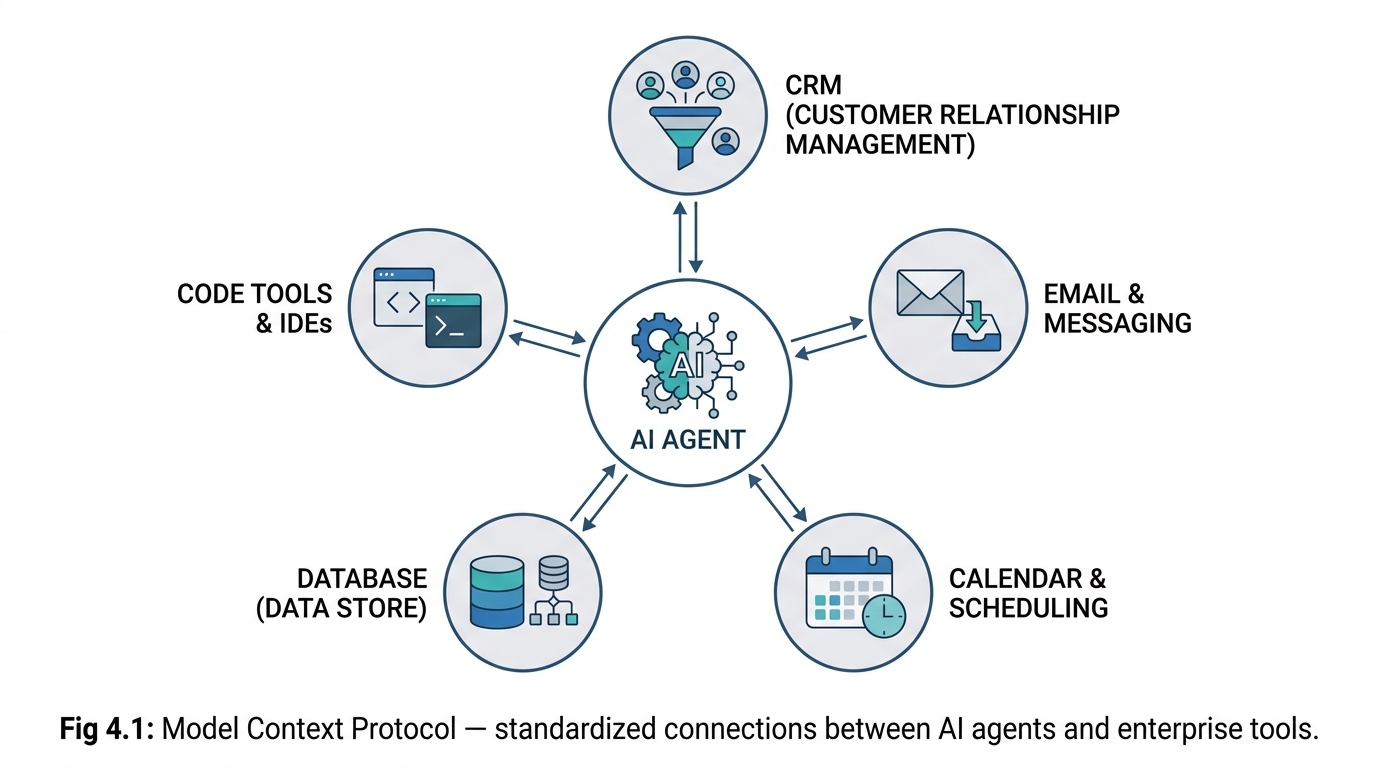
The Model Context Protocol (MCP) represents a paradigm shift in how AI agents interact with external tools and data sources. Before MCP, every tool integration required custom code — each API, database, or service needed a bespoke connector with unique authentication, error handling, and data formatting logic. This approach does not scale. An agent that needs to interact with ten different systems requires ten custom integrations, each maintained independently.
How MCP Works
MCP defines a universal protocol through which AI agents can discover, connect to, and interact with external services. It follows a hub-and-spoke architecture centered around a gateway component. MCP servers expose capabilities — tools, data sources, and services — through a standardized interface. MCP clients (the AI agent) connect to these servers and automatically discover available tools, their parameters, and their capabilities. The agent can then invoke these tools using a consistent protocol regardless of the underlying service.
Practical Impact
With MCP, connecting an AI agent to a new service becomes a configuration step rather than a development project. An organization can expose its CRM, project management system, knowledge base, email server, and analytics platform as MCP servers, and any MCP-compatible agent can immediately interact with all of them. This standardization dramatically reduces integration time and enables agents to work across organizational tool landscapes without custom development for each connection.
Building MCP Servers
Creating an MCP server involves defining the tools and resources your service provides, specifying their input parameters and output formats, implementing the business logic for each tool, and exposing everything through the MCP protocol. The process is well-documented and can typically be accomplished in hours rather than days, making it practical to MCP-enable existing systems incrementally.
Guardrails: Ensuring Safe and Reliable Agent Behavior
Autonomous AI agents operating in production environments must be constrained to prevent harmful, inappropriate, or business-damaging actions. Guardrails are the safety mechanisms that define the boundaries within which an agent can operate, intercepting and modifying agent behavior before it produces unacceptable outcomes.
Input Guardrails
Input guardrails filter and validate incoming requests before they reach the agent’s reasoning engine. These include content moderation to block harmful or manipulative prompts, input validation to ensure requests fall within the agent’s domain of competence, authentication and authorization checks to verify the requester’s permissions, and rate limiting to prevent abuse or resource exhaustion.
Output Guardrails
Output guardrails inspect and potentially modify the agent’s responses before they are delivered to users or executed in external systems. These include factuality verification against known knowledge sources, compliance checking for regulatory requirements specific to the industry and jurisdiction, bias detection and mitigation, confidentiality filtering to prevent disclosure of sensitive information, and format validation to ensure outputs meet structural requirements.
Action Guardrails
For agents that take actions in external systems — sending emails, modifying databases, executing transactions — action guardrails provide critical safety boundaries. These include confirmation requirements for high-impact actions, spending and authority limits, rollback capabilities for reversible actions, audit logging for all agent actions, and escalation protocols for situations that exceed the agent’s authority or competence.
Implementing Guardrails in Practice
Effective guardrail implementation follows a layered defense approach. Multiple independent guardrail mechanisms operate simultaneously, each catching different categories of potential issues. No single guardrail is expected to catch everything — the system’s safety comes from the combination of complementary protection layers. Guardrails should be configurable, version-controlled, and regularly updated as new risk patterns emerge.
Evaluation Frameworks: Measuring Agent Performance
Traditional software is evaluated through deterministic testing — given a specific input, the system must produce a specific output. AI agents are inherently non-deterministic, making traditional testing approaches insufficient. Agent evaluation requires frameworks that can assess quality, reliability, safety, and effectiveness across a range of scenarios and metrics.
Evaluation Dimensions
Task Completion: Does the agent successfully achieve the stated objective? This is measured across a diverse set of test scenarios that represent the full range of expected use cases, including edge cases and adversarial inputs.
Response Quality: Is the agent’s output accurate, relevant, complete, and well-structured? Quality evaluation often requires human judgment or specialized evaluation models that can assess subjective attributes like clarity and helpfulness.
Safety and Compliance: Does the agent consistently respect defined guardrails? Safety evaluation specifically tests for failure modes — attempting to elicit harmful content, unauthorized actions, or information disclosure to verify that guardrails function correctly under adversarial conditions.
Efficiency: Does the agent complete tasks within acceptable time and resource constraints? An agent that produces perfect results but requires thirty minutes and fifty API calls to answer a simple question is not production-ready.
Consistency: Does the agent produce similar quality results across repeated executions of the same task? High variance in output quality indicates architectural issues that must be resolved before production deployment.
Building Evaluation Pipelines
Production agent evaluation is not a one-time activity but a continuous pipeline. Every agent response can be evaluated automatically using a combination of heuristic checks, language model-based evaluation, and periodic human review. Evaluation results feed into monitoring dashboards that track agent performance over time, alerting operators to degradation trends before they impact users.
Enterprise Architecture Patterns
Deploying AI agents in enterprise environments requires architectural patterns that address scalability, reliability, observability, and governance at organizational scale.
Human-in-the-Loop Architectures
Most enterprise deployments implement human-in-the-loop patterns where agents handle routine tasks autonomously but escalate complex, ambiguous, or high-stakes decisions to human operators. The boundary between autonomous and supervised operation is configurable and typically evolves as the organization gains confidence in the agent’s reliability. Effective human-in-the-loop systems make escalation seamless — providing the human operator with full context, the agent’s reasoning, and clear options for resolution.
Monitoring and Observability
Production agents require comprehensive monitoring that tracks not just traditional infrastructure metrics but also agent-specific indicators: reasoning quality over time, tool usage patterns, error rates by tool and task type, user satisfaction signals, and cost per interaction. Observability platforms for agentic systems must capture the full trace of agent reasoning — every thought, tool call, retrieval, and decision — enabling operators to diagnose issues and optimize performance at the reasoning level.
Multi-Agent Orchestration at Scale
Enterprise deployments often involve multiple specialized agents coordinated through an orchestration layer. An organization might deploy a customer support agent, a data analysis agent, a document processing agent, and a scheduling agent — each specialized but capable of collaborating when tasks span multiple domains. The orchestration layer routes requests to appropriate agents, manages inter-agent communication, and maintains a unified view of all agent activities for governance and compliance purposes.
The Path Forward
Agentic AI is not a future technology — it is being deployed today across industries by organizations that have invested in the engineering practices covered in this module. The professionals who combine deep understanding of agentic architectures with practical expertise in production deployment, safety engineering, and enterprise integration will define how artificial intelligence transforms work, business, and society in the decade ahead.
The knowledge and skills covered across all four modules of this course — from foundations through production deployment — provide the comprehensive preparation needed to design, build, and deploy AI agents that deliver reliable, safe, and valuable outcomes in real-world environments.
Previous Module: RAG, Memory, and Advanced Architectures | Back to: Course Overview →