Module 3 of the Agentic AI Mastery Course by Dr. Ananjan Maiti
Why Retrieval-Augmented Generation Changes Everything
Large language models are trained on vast datasets, but their knowledge is frozen at the point of training. They cannot access proprietary company data, recent developments, or specialized domain knowledge that was not included in their training corpus. This fundamental limitation — known as the knowledge cutoff problem — makes standalone language models unreliable for applications requiring current, accurate, or organization-specific information.
Retrieval-Augmented Generation (RAG) solves this problem by connecting language models to external knowledge sources at inference time. Rather than relying solely on parametric knowledge stored in model weights, RAG systems retrieve relevant documents from external databases and inject them into the model’s context before generating a response. This architectural pattern has become the standard approach for building knowledge-grounded AI applications across enterprise, research, and consumer domains.
The RAG Pipeline: From Documents to Intelligent Responses
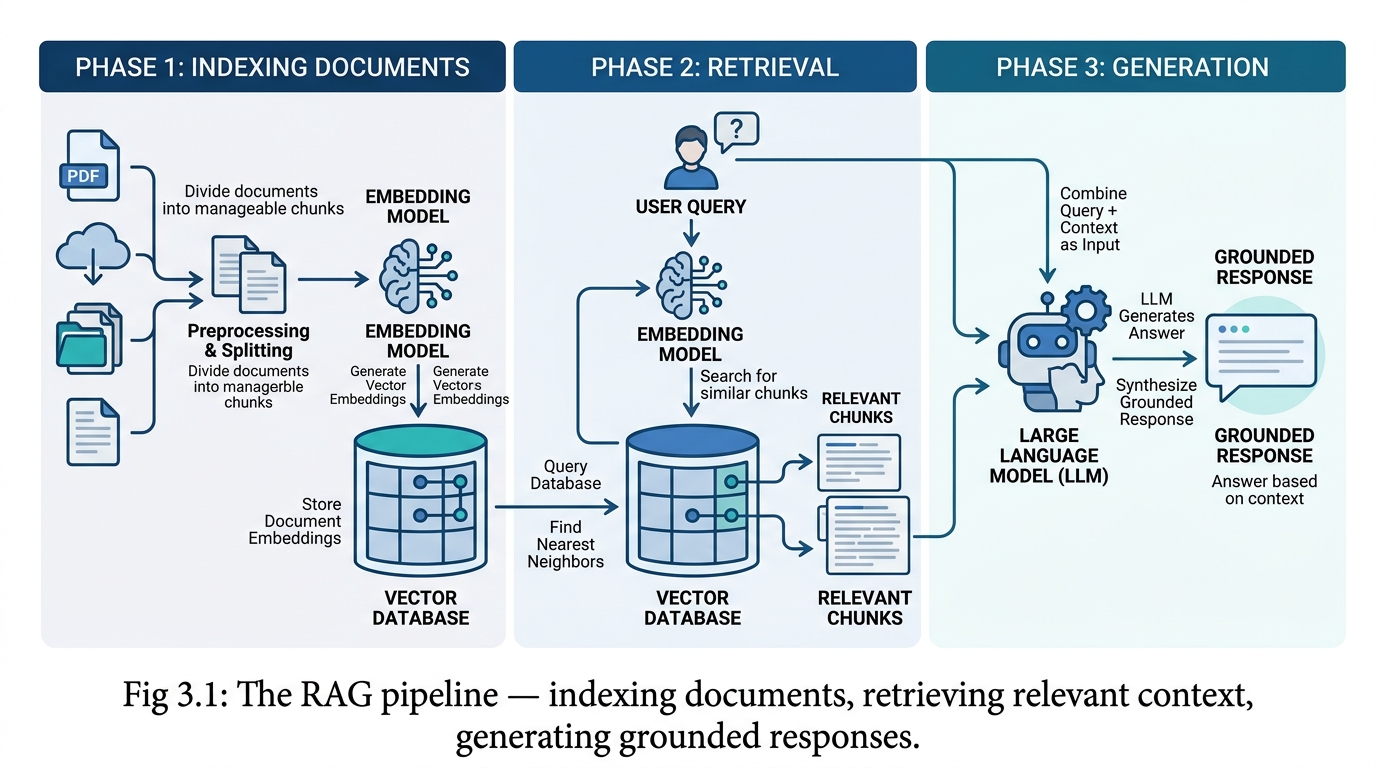
A standard RAG pipeline consists of three core phases: indexing, retrieval, and generation.
Document Indexing
The indexing phase transforms raw documents — PDFs, web pages, databases, spreadsheets, emails, code repositories — into a searchable format. Documents are split into chunks of manageable size, each chunk is converted into a numerical vector representation using an embedding model, and these vectors are stored in a specialized vector database. Popular vector databases include Pinecone, Weaviate, Chroma, FAISS, and Qdrant, each optimized for different scale and deployment requirements.
Retrieval
When a user submits a query, the retrieval phase converts the query into the same vector space as the indexed documents and performs a similarity search to identify the most relevant chunks. Advanced retrieval strategies go beyond simple vector similarity to include keyword matching (BM25), hybrid search combining vector and keyword approaches, metadata filtering, and re-ranking models that refine the initial results for maximum relevance.
Generation
The retrieved documents are combined with the original query and passed to the language model as augmented context. The model generates a response grounded in the retrieved information, producing answers that are both contextually relevant and factually grounded in the source material. Well-designed RAG systems include source attribution, allowing users to verify the provenance of every claim.
From Basic RAG to Agentic RAG
Basic RAG follows a fixed pipeline: retrieve then generate. While effective for straightforward question-answering, this rigid approach fails when the information need is complex, ambiguous, or requires multi-step reasoning.
Agentic RAG transforms the retrieval process from a static pipeline into a dynamic, agent-driven workflow. Instead of performing a single retrieval step, an agentic RAG system can decide when to retrieve, what to retrieve, which knowledge sources to query, how to reformulate queries for better results, and whether the retrieved information is sufficient or requires additional search iterations.
Key Capabilities of Agentic RAG
Query Planning: The agent analyzes the original question and determines what information is needed before retrieving anything. A complex question like “How does our product’s pricing compare to competitors, and what are customers saying about the price difference?” requires retrieving from internal pricing databases, competitor intelligence sources, and customer feedback systems — three distinct retrieval operations that a basic RAG system would conflate into a single search.
Adaptive Retrieval: The agent evaluates retrieved results and decides whether they are sufficient. If the initial retrieval returns irrelevant or incomplete information, the agent reformulates the query, searches different sources, or applies filtering criteria to improve results. This iterative refinement process mirrors how human researchers approach complex information needs.
Multi-Source Orchestration: Agentic RAG systems can query multiple knowledge sources simultaneously — internal databases, public search engines, specialized APIs, and structured data repositories — then synthesize the results into a unified, coherent response. This capability is essential for enterprise applications where relevant information is distributed across multiple systems.
Vectorless RAG: Beyond Embedding-Based Retrieval
While vector databases have become the default infrastructure for RAG systems, an emerging approach called vectorless RAG challenges this assumption. Vectorless RAG uses structured reasoning and direct data access methods instead of embedding-based similarity search to retrieve relevant information.
In vectorless RAG, the agent directly queries structured data sources — SQL databases, knowledge graphs, APIs, or indexed document stores — using precise queries generated by the language model. Rather than converting everything into vectors and performing approximate similarity search, the system constructs exact queries that return precisely the information needed. This approach offers several advantages: deterministic retrieval results, no information loss from chunking and embedding, compatibility with existing data infrastructure, and often lower latency for structured data queries.
The most effective modern RAG architectures combine both approaches — using vector search for unstructured text and vectorless methods for structured data — creating hybrid retrieval systems that leverage the strengths of each approach.
Memory Systems for Persistent AI Agents
Memory is what transforms a stateless language model into a persistent, learning assistant. Without memory, every interaction starts from zero — the agent cannot build on previous conversations, learn from past mistakes, or accumulate expertise over time. Effective memory systems are therefore essential for any agent that needs to function as a reliable, long-term collaborator.
Short-Term Memory (Working Context)
Short-term memory maintains the context of the current task or conversation session. This includes the conversation history, intermediate results from tool calls, the current state of the agent’s plan, and any temporary data needed for the active workflow. Short-term memory is typically implemented as the language model’s context window, supplemented by explicit state management in frameworks like LangGraph.
Long-Term Memory (Persistent Knowledge)
Long-term memory persists across sessions, enabling the agent to recall information from previous interactions days, weeks, or months later. This can include user preferences and behavioral patterns, project histories and outcomes, learned domain knowledge, successful strategies and common failure patterns, and organizational context. Long-term memory is typically implemented using vector databases, key-value stores, or graph databases that the agent queries at the beginning of each interaction to reconstruct relevant context.
Episodic vs. Semantic Memory
Advanced memory architectures distinguish between episodic memory (specific events and interactions) and semantic memory (generalized knowledge and patterns). An agent might store the episodic memory that “the user preferred formal tone in last Tuesday’s report” and the semantic memory that “this user generally prefers formal communication.” This distinction enables agents to balance specific contextual recall with generalized behavioral adaptation.
Planning Architectures for Complex Problem Solving
Planning is the cognitive mechanism that enables agents to tackle problems too complex for single-step solutions. Several planning architectures have emerged as effective approaches for different types of problems.
Chain-of-Thought Planning
The simplest planning approach prompts the agent to reason through a problem step by step before taking action. By making the reasoning process explicit, chain-of-thought planning improves the quality of decisions and makes the agent’s logic auditable.
Tree-of-Thought Planning
Tree-of-thought planning extends chain-of-thought by exploring multiple reasoning paths simultaneously. The agent generates several possible approaches, evaluates each one, prunes unpromising branches, and focuses resources on the most promising strategies. This approach excels for problems with multiple valid solution paths.
Self-Reflection and Iterative Refinement
The most sophisticated planning architectures include self-reflection mechanisms where the agent evaluates its own output, identifies weaknesses or errors, and iteratively improves the result. This metacognitive capability — thinking about thinking — enables agents to achieve quality levels that approach expert human performance on structured tasks.
Previous Module: Frameworks and Tools | Next Module: Production-Ready AI Agents →